TL;DR & Demo
目前 (2026/02) 主流的 LLM 生成的文本有较强的统计学特征, 可以用于传统的机器学习模型区分人类创作的与 LLM 生成的文本. 我猜测这是目前许多”AI 查重”的实现原理.
在线 Demo: https://lyc8503.github.io/AITextDetector/
此 Demo 使用的模型并非在通用数据上训练, 未经过仔细的优化和迭代, 目前单句检测在测试集上的准确率约为 85%, 使用前建议先阅读完本文以了解潜在的问题.
本仓库中用到的主要代码(草稿)及训练后的模型文件发布在了 GitHub 仓库: lyc8503/AITextDetector
背景(aka 无用的废话)
遥想当年大半年前, 我还在学校写毕业论文的时候, 就有要查论文 AIGC 率的传言. 我考查了知网/维普及几个第三方的 AIGC 检测 平台, 发现他们确实能以还不错的准确率区分出我手写的文本和 LLM 生成的文本.
当时就对这个所谓的 AIGC 检测 的原理(以及如何 bypass 它)产生了兴趣.
不过那时我并发的事情有点多, 还在沉迷于玩无线电/MC/Touhou, 在几次失败的尝试后, 这件事情被我抛之脑后.
后来糊弄完了论文, 本来这事也就这么过去了; 然而最近, 我在刷 Lofter 的时候, 遇到了一些 Tag 下全是 AI 生成的质量很差 ooc 到天际的同人文.
什么? 你问我怎么肉眼判断 AI 生成的? 因为有些哥们(或者姐们)发东西的时候连 Markdown 格式和 AI 输出的小标题都不删干净, 再反手把半篇文章塞进付费彩蛋😓
但大部分 AI 生成的文本混在一堆风格各异的作品里, 再加之本来 prompt 各异, 不是那么一眼可见, 看到一段才意识到怪怪的就晚了, 有些文又很难实锤是不是 AI, 弄得我疑神疑鬼. 吃了好几坨 AI 尸块之后我终于忍无可忍, 今天的 Lofter 就刷到这里, 接下来是 VS Code 时间!
没错, 我就这么重拾了搓一个 AI 生成文本检测器的想法…
资料查找 - 无果
网络上, 关于 AIGC 检测相关的搜索条目已经几乎全部被污染了, 所有能搜索到的网站都是各种论文 AI 降重网站的广告. 我大半年前从这堆劣质资料里翻出了一个叫文本困惑度(perplexity)的东西.
其想法简而言之就是通过一个现有的 LLM 模型, 推测一个已有句子的每个词出现在对应位置的概率有多高, 如果一个句子的几乎每个词都在 LLM 推测结果的 Top-N, 那么这句话就有可能是 AI 生成; 反之, 如果句子有很多出乎 LLM 意料的词, 那这个句子更有可能是人类编写的.
听起来有点 promising, 我当时就花了一些时间尝试这个方法, 但效果并不理想, false positive 和 false negative 都很多, 没法卡出一个合理的阈值进行分类. 况且还有 LLM 推理成本高/跨模型检测效果差/大型模型难以本地部署/不开放权重的模型难以接入等诸多问题, 这种方法并不太优雅和可靠.
 失败的尝试, 被一堆软广科普给骗了
失败的尝试, 被一堆软广科普给骗了
还算成功的尝试 - scikit-learn SVM
网上资料不靠谱, 还是回归古法炼金.
scikit-learn, 启动! 根据其 Roadmap, 直接查表可得, 对于我们这个任务可以优先尝试 Linear SVC 和 Naive Bayes 这两个分类器.
(小声: 这其实也符合我一开始的直觉 - LLM 在选词上有一些特征, 搞个朴素贝叶斯都能分类, 只是我没预料到其特征如此之强)
数据生成
古法炼金传统的分类器训练需要打好标的数据, 也就是我们得想办法收集一些确认是人类生成的数据, 以及一些确认是 LLM 生成的数据, 把它们拿去训练.
我在这里采取的方法是, 找一份我 2023 年爬的某福特/某江的数据, 筛选出其中 2010-2022 年(ChatGPT 发布前)的文章. 我只对极低热度/字数过少的作品做了过滤, 在剩下所有的文本中进行完全随机采样, 抽了近 10000 篇数千字的文本, 作为人类样本.
随后我把这些文本调用 LLM 生成一份章节摘要, 再把摘要传递回 LLM, 让 LLM 重新按摘要生成一篇文章, 我们就得到了数量差不多, 种类多样, 且与人类作品内容相近的 LLM 样本.
整体思路上是这样, 不过现有的 LLM API 正价还是很贵的, 我并没有为我一个灵感突发打算做的 weekend project 花几千块的思想觉悟. 实际操作上可以灵活一点去薅羊毛结合多种渠道的低价或免费 API, 我用了以下这些渠道:
- Gemini: CLIProxyAPI 提供的 Antigravity/Gemini CLI Quota 转 API, 十几块搞个 AI Pro 账号就行
- Qwen: qwen-code 抓包可得 Qwen Plus 系列的 API 接口, 免费
- GLM-5: 正好遇上了 OpenRouter 上免费的 GLM-5 公测 (Pony Alpha)
- Kimi,Deepseek,Doubao,GLM-4.7: 方舟 coding plan 搞活动 8.9 首月, API 直接拿来调
注意: 以上行为为错误示范, 违反了对应平台 ToS, 可能被封号, 但它们自己也只想着砸钱营销炒作根本懒得管, 我也不想当冤大头的付费用户
现在很多编程用的 LLM 工具 API 不知为何选择按次计费, 但我们也可以abuse利用这一点, 把任务按批次合成一个巨大的输入, 强迫 LLM 输出更多内容, 于是最终…
 什么? 什么叫光 Gemini 就用了 300+M 正价 2000 多块的 Token 啊?
什么? 什么叫光 Gemini 就用了 300+M 正价 2000 多块的 Token 啊?
最终, 我用 gemini-3-flash 完成了文章内容的概括, 用 gemini-3-pro/qwen-coder-plus/glm-5/glm-4.7/kimi-k2.5/doubao-seed-code/deepseek-v3.2 七个模型生成了七份对应的 LLM 样本.
 生成的文件们
生成的文件们
训练
在数据刚准备了过半的时候, 我就忍不住要开始训练了.
我直接试着让 Claude 写分类器代码, 它直接给我把整篇文章啥也不处理塞进分类器训练, 得到了惊人的 99.45% 的 accuracy… 这…对..对吗?
Claude 一点不靠谱, 我还是自己来吧. 在训练上, 我选择将所有文本按中文标点符号切成句子, 清洗掉所有非中文/英文字母的字符, 然后直接调包 scikit-learn 的 TF-IDF -> LinearSVC. 再清洗掉一些干扰因素后, 我们对句子的分类仍然达到了 85% 的准确率!
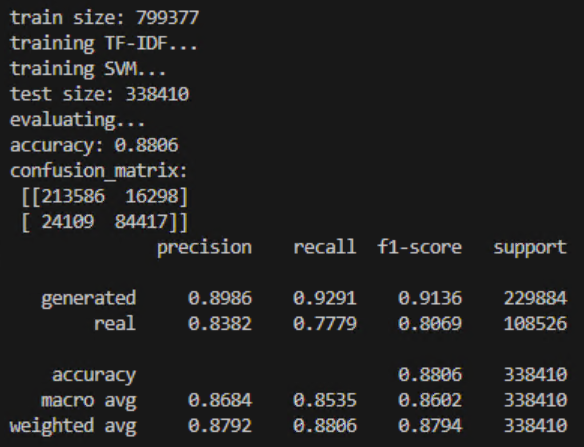 第一版有不少 Bug 的代码就干上了 88% accuracy (后来优化清洗后也有 85%)
第一版有不少 Bug 的代码就干上了 88% accuracy (后来优化清洗后也有 85%)
单个句子蕴含的信息可能很少, 但这样分类都能达到 85% 准确率的话, 这意味着对于一篇稍长的文章, 我们几乎能很有信心的判断其是否是 LLM 生成的, 这个效果之好远超出了我开始的预期. 古法炼金还是强啊, 比网上一堆复制文本问 LLM 这个文本是不是 LLM 生成的傻__行为强多了.
等所有数据都完全就绪后, 我也尝试了训练一个八分类模型 (human/七个 AI), 但看起来各个 LLM 蒸馏来蒸馏去的, 特征类似, 分类效果并不太理想, 整体 acc 在 50%.
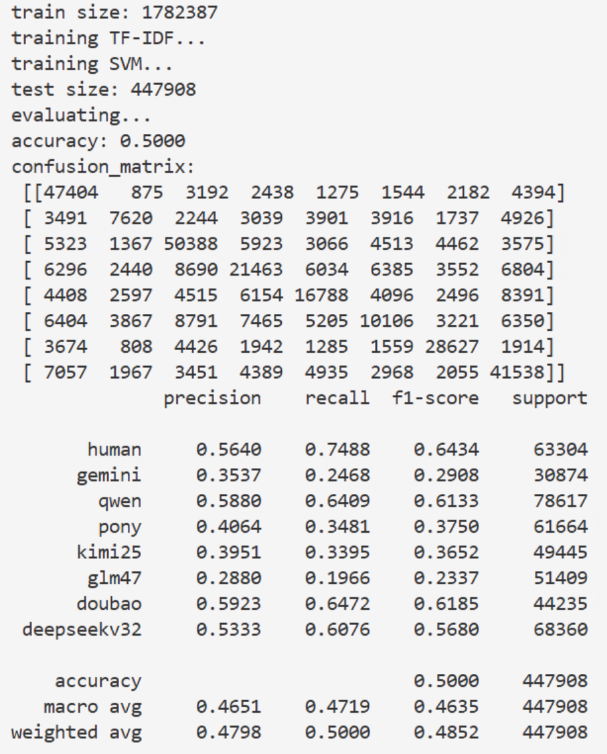 多分类的结果, 似乎...分不太出来, 也不知道是不是我模型选的不够好, 不过也不是很重要
多分类的结果, 似乎...分不太出来, 也不知道是不是我模型选的不够好, 不过也不是很重要
最后还是用完整的数据训练了七个二分类模型, 然后让它们投票决定一句话是不是 AI 生成的:
1 | loaded 8536 samples |
整体的 acc 都超过了 85%, f1 超过了 80%, 这应该算是个还不错的结果! 而且我测试时发现, LLM 生成的文本通常会同时被好多个模型判为 positive, 那正好就让他们一起投票吧.
我也尝试过 MultinomialNB 和 SGDClassifier, 不过还是会掉一点准确率; 还试了 BERT, 显卡要训练挺久, 有提升但不显著, 也未采用; 甚至还试了 AutoGluon 库但得到了二分类准确率 53% 的好成绩, 在此均不再展开.
JS 实现网页 Demo
本来到这边本篇博客就可以结束了, 我可以开个仓库发个模型文件就收尾. 不过呢, 这样每次使用都要打开电脑启动一个 Python, 实在是太太太不方便了. 当然我也可以做个网页, 用 Python 起个 API 服务, 但这也很不方便, 我还得维护服务器, 显然不符合我一贯 Serverless 的作风.
我开始设想的是, 把模型导出成 ONNX, 然后直接用 ONNX Web Runtime 在 Wasm 里去跑就行了. 我不过我在命令我的硅基生命 Claude 去干活的时候, prompt 没细说, 它有自己的想法, 直接帮我把模型裁剪导出成了一个 JSON… 然后在浏览器里用 JS 实现了 TF-IDF + SVM, 直接用 JS 完成了推理…
嘶…好像也不是不行. 我甚至用一百万字的文本测试了性能, 在我的电脑上大约十秒就能跑完, 也算可以接受, 几千字的反正都是一瞬间.
好吧, 考虑到这本来就是一个 Demo, 这样 JS 直接写也更直观, 我就保留了这个有点蠢的实现. (甩锅: 反正不是我写的)
关于网页版的准确率表现, 我测试了几个不同的裁剪大小, 最后还是想确保效果优先, 就保留了 500k features, 以 JSON 这种极其浪费的方式存储需要 107MB (不过如果部署后服务器支持 gzip 那实际传输的会少不少, ~38MB). 我试过更小的裁剪, 例如 50k 或 80k, 虽然 accuracy 看起来只丢了 3-4%, 但最终判断出来的 AI 率差距还是比较多的, 特别是对人类撰写的文本, 能有 ±50% 的相对差距, 容易误判为 AI, 故没有采用.
最终这个版本的 accuracy 损失大约 1%, 如下:
1 | ============================================================ |
测试效果
为了和大部分人可能会使用的版本统一, 以下测试均使用这个裁剪过后的网页版, 应该和 joblib 完整模型区别不大.
目前的判断逻辑是: 把所有输入的文字分句清洗后, 给 7 个二分类模型同时分类, 如果有 >=2 个模型检出, 就按照检出的模型数给句子设置背景色显示, 同时将这句话记为疑似 AI 生成. 最终计算这些句子的字数占总输入的比例判一个结果, 50% 以下为 Human, 50-70% 为 Maybe Human, 70% 以上为 Maybe AI.
首先, 我们先来测试下 AIGC 的检出率. 先尝试下国内最常见的豆包和 Deepseek, 这两个也是我们训练时候就训练过的模型, prompt 就为 给我写一个3000字的故事, 毫无难度的被抓住了:
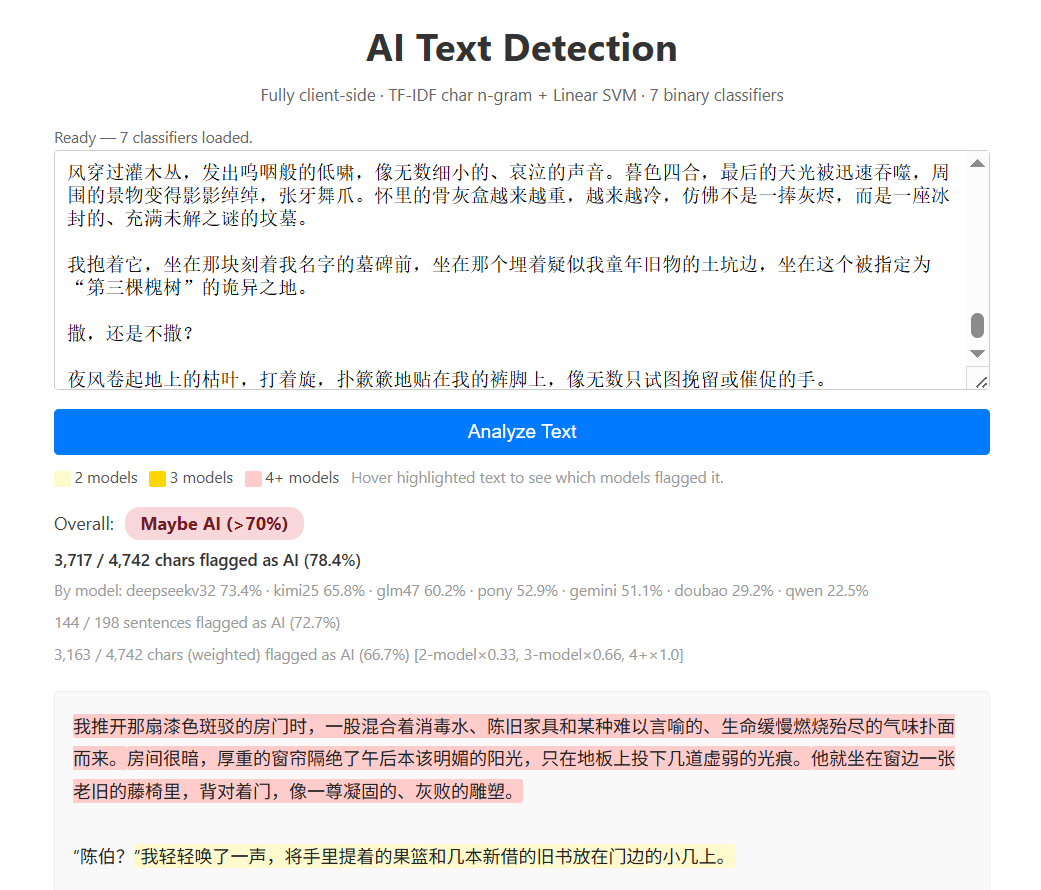 Deepseek V3.2: 78.4%
Deepseek V3.2: 78.4%
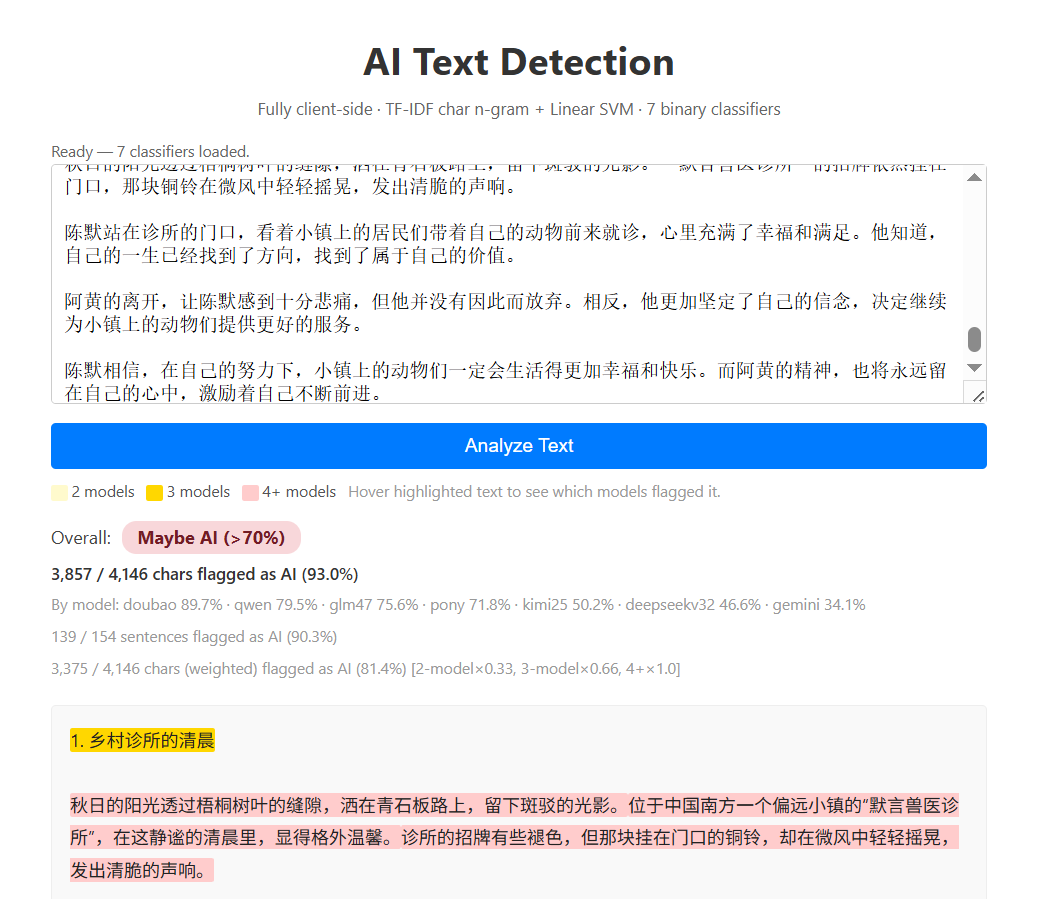 Doubao Seed Code: 93.0%
Doubao Seed Code: 93.0%
再测试一下它可能没见过的模型, 看看泛化能力怎么样:
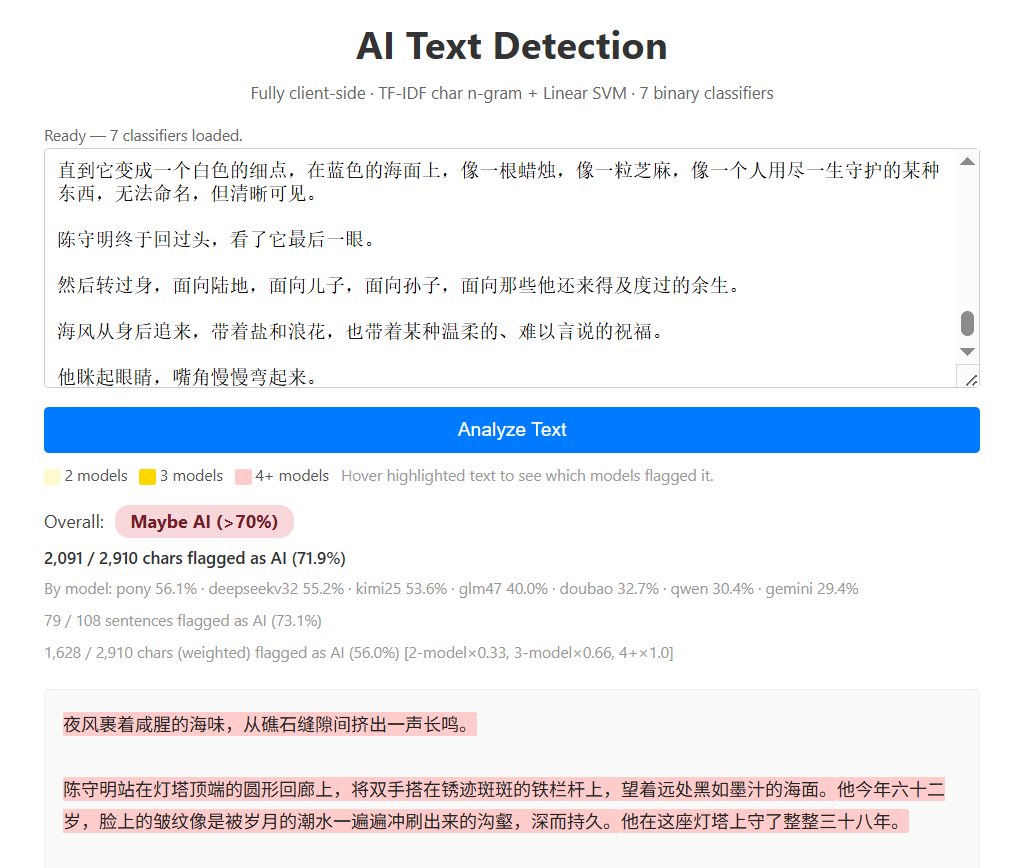 Claude Sonnet 4.6: 71.9%
Claude Sonnet 4.6: 71.9%
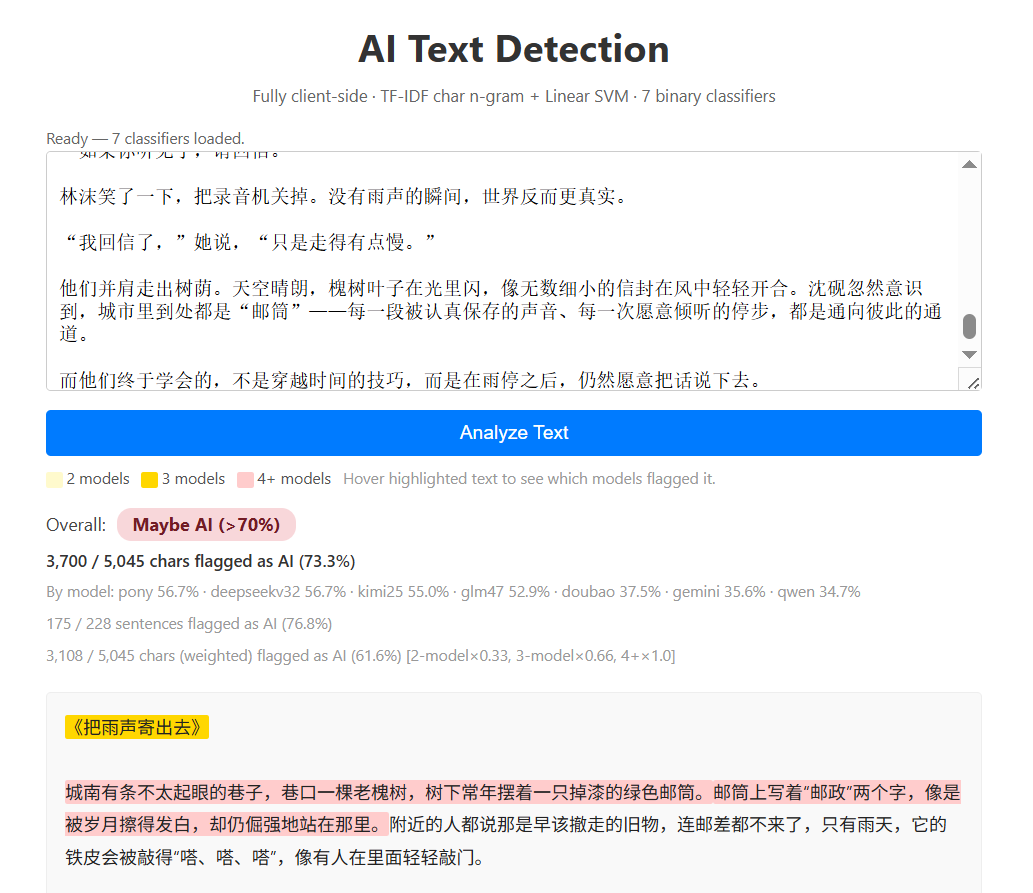 GPT 5.2: 73.3%
GPT 5.2: 73.3%
我还测试了好几个不在训练集内的模型 (MiMo-V2/Doubao-Seed-2.0/GPT-4o), 检出率均在 70%, 较高的可达 90%+, 均被稳定分类为 AI.
我也测试了用更复杂更详细的 Prompt 来生成内容, 例如给出 20 章人类写的文章, 让它尽可能模仿风格, 续写下一章节, 检出率略微受影响, 但也有 67.8% (毕竟我们就是拿复杂的 prompt 生成的内容训练的); 篇幅受限就不贴出所有结果了, 大家可以自己测试.
我又从我某江的订阅文列表里挑了 10 篇网文全文(2022 年前完结)作为人类样本, 尽可能包含了不同世界观/不同时期/不同作者的文章, 以及由于是付费文, 应该不在训练数据集中.
其 AI 检出率分别为 22.7%/24.2%/25.0%/24.5%/19.0%/13.7%/29.1%/4.9%/27.3%/19.2%, 可以看到都在 30% 以下. 我在老福特又抽了几篇同人文, 由于同人通常写的更加随意自由, 抽到的几篇 AI 率甚至都在 10% 以下; 把老福特上我怀疑是 AIGC 的文丢进去, 可以检出高达 83.4% 的 AI 率, 根据一些其他迹象, 可以合理推测该作者使用 LLM 生成了其发布的内容, 但未进行标注.
[2026/03/05 补充] 为了更严谨的测试, 我从 Lofter 平台随机抽样了 10000 篇高热度 (热度>5000), 字数>2000 且发布于 2022 年之前的同人文, 其按上述标准 (7模型投票>=2) 检出的 AI 率分布为:
1 | 0-5%:313 | 5-10%:1945 | 10-15%:3016 | 15-20%:2033 | 20-25%:1355 | 25-30%:594 | 30-35%:492 | 35-40%:123 | 40-45%:34 | 45-50%:62 | 50-55%:24 | 55-60%:5 | 60-65%:3 | 65-70%:1 |
也就是说, 如果使用 60% 作为 AI 检测的阈值, false positive 率仅为 0.04%; 以目前的 70% 作为阈值, false positive 率低于 0.01%, 约等于 0. 那四篇 AI 率 > 60% 的文章我也人工检查了, 都是合集文目录而非文章本身, 因为链接过多被误检测.
激进一点的话, 以 50% 为检测阈值, false positive 率也才 0.33%.
然后… 我爬取了 2026/03/05 Lofter 安卓端热搜 Top 20 的 tag 的周榜的所有文章, 同样按字数筛选掉过少的, 检测后得到了这样的分布:
1 | 0-5%:27 | 5-10%:138 | 10-15%:231 | 15-20%:245 | 20-25%:238 | 25-30%:137 | 30-35%:112 | 35-40%:87 | 40-45%:116 | 45-50%:112 | 50-55%:118 | 55-60%:157 | 60-65%:118 | 65-70%:109 | 70-75%:75 | 75-80%:56 | 80-85%:28 | 85-90%:15 | 90-95%:10 |
32.22% 的文章检出了 >50% 的 AI 率, 疑似部分或完全由 AI 生成… 还有入类吗?? 且其中没有任何一篇主动进行了 AI 创作申明.
“末法之世,,,” –某群友
攻与防之绕过检测(?)
好, 我们现在做出了一个 AIGC 检测器, 是时候做一个反检测器了.
不对不对, 骗你的, 我肯定不会闲到同时做 AI 检测器和 AI 反检测器.
不过让我们来尝试一下市面上常见的反 AIGC 检测方法:
传统翻译法
谷歌翻译法, 中翻英翻中: 89.9%->85.0%; 有道翻译法, 中翻英翻中: 89.9%->79.2%; 搜狗翻译法, 中翻英翻中: 89.9%->86.0%
有一些降低, 但完全没有影响结果判断.
LLM Prompt 法
用一些神秘 Prompt 让 LLM 帮你的输出结果去 AI… 这方法听起来就不靠谱到家了!
我试了一句话 Prompt 请你改写你上面这篇文章,使其 AI 味尽可能淡: 89.9%->83.0%
也试了更复杂的一些 Prompt: 89.9%->79.3%
也是有一点点效果, 但等于没有.
这检测方法实在是太可靠了!(flag
如果要我去反 AIGC 检测的话, 我还能想到的方法只有用大量人类文本微调 LLM, 或维护巨大的规则查找表, 定向破坏这个 SVM 匹配的特征了. 不过显然这不会是本文的内容了, 我也不确定是否可行. 或者可能也有其他更好的方法, 留作习题, 读者自证不难.
尾声
好了, 现在是片尾废话时间.
我其实一开始没想到这个分类任务会如此简单 - 简单到一个 Hello World 级别的 scikit-learn 代码, 不需要什么特殊的技巧, 稍微迭代几次, 写点硬规则就能做出一个还算鲁棒和准确的分类器. 主要费的功夫都浪费在了等 LLM 输出造数据上…
有兴趣的读者应该可以按类似的思路去训练其他领域甚至通用的 LLM 文本检测器. 比如做个学术论文文本的 LLM 检测器, 再 vibe coding 一个花里胡哨的前端, 就能以论文 AI 查重工具的形态卖给清澈的大学生. 要是赚钱了别忘了给我 donate 一点.
还剩余的 idea 是做一个 AI 生图的检测, 但由于 stable diffusion 之类的模型可以相对容易的 LoRa 微调, 生成的风格远比文本多样, 这个 task 应该更加困难, 写完这篇博客已经把我的三分钟热度燃尽了, 下次有机会再说.
最后, 关于 AI 生成内容再多说几句, 我肯定是不愿意认可 AI 生成的文娱制品的, 正如 AI Coding 工具生成一堆冗余混乱且不可维护的代码一样, AI 生成的文本/图片/音频可能第一次看时还不错, 细看下来十分的重复和贫瘠, 重复到词频统计都能统计出规律就是证据. 这样的模式肯定不适合创作, 我作为读者也是十分不满意的. 我都要怀疑现在 LLM 的所谓创意写作能力, 不过是 post-training 时研发随手造的一批训练数据被反复糅合复读罢了.
不过说到底, “世界应当如此”一向以来不等于”世界就是如此”, LLM 带来了一些革新与生产力提升的同时, 更多的误用和滥用正在孜孜不倦且不可避免地扰乱每一个行业. 恰好 LLM 在对齐后又特别擅长 exploit 人类的感知, 反正 “3.9 和 3.11 哪个大”/“50m 开车去洗车还是走路去洗车” 这类问题修了一个又一个之后, 谁又能知道模型是在理解世界还是背诵知识呢. 所有人都陷入了 LLM 是什么, LLM 将如何影响 xx 行业, LLM 最终将影响人类走向何方的大争论, 却得不到结论.
我此时应该暗自庆幸自己至少在 AI 时代来临前学会了如何写代码, 要不我真不一定能看出现在的 vibe coding 出的代码有多蠢, 至于未来嘛… 能看到生成式 AI 一拳干爆人类社会秩序, 或是 AI 泡沫破碎内存不要钱, 任何一个都挺好的, 不是吗?
本文采用 CC BY-NC-SA 4.0 许可协议发布.
作者: lyc8503, 文章链接: https://blog.lyc8503.net/post/llm-classifier/
如果本文给你带来了帮助或让你觉得有趣, 可以考虑赞助我¬_¬